
Scenario
In a Security Operations Center (SOC), analysts are constantly overloaded with data from various sources, such as network traffic logs, intrusion detection systems, vulnerability scanners, and endpoint security software. Effectively sifting through this massive amount of information can overwhelm any analyst. Mastering advanced queries can significantly streamline this process, enabling analysts to extract critical insights and make well-informed decisions.
In this room, we will delve into advanced queries for Kibana, an integral component of the Elastic Stack (ELK) that provides visualization and analytics capabilities for data stored in Elasticsearch.
Learning objectives
- Learn about different advanced queries
- Learning about different query syntaxes (Kibana Query Language and Lucene)
Room Prerequisites
- This room assumes that you know the basics of navigating the Kibana dashboard and are familiar with the Kibana Query Language, as we will be heading straight to talking about advanced queries. If you aren’t, then this room will be a good primer on this topic.
- Regular expressions, specifically in Kibana, will be discussed in Task 7. The basic syntax and how regex works will not be addressed, so familiarity and experience using regular expressions on any engine or programming language will significantly help.
Setting up and connecting to Kibana
Start the virtual machine by clicking on the green “Start Machine” button on the upper right section of this task. Let the VM load for around 5 minutes, as it will run in the background. To access the Kibana dashboard, you can do it in two ways:
Connect via OpenVPN (More info here) and then type the machine’s IP
https://10-10-69-18.p.thmlabs.com/on your browser’s address bar.Log in to AttackBox VM, open the web browser inside AttackBox, and then type the machine’s IP
http://10.10.69.18on the address bar.
You’ll be presented with the Kibana log in screen. Enter elastic for the username and elastic for the password.
When done correctly, you should see the page below: 
A Primer on Advanced Queries
Different Syntaxes
Kibana supports two types of syntax languages for querying in Kibana:
1
2
- 'KQL (Kibana Query Language)' : Kibana Query Language (KQL) is a user-friendly query language developed by Elastic specifically for Kibana. It provides autocomplete suggestions and supports filtering using various operators and functions.
- 'Lucene Query Syntax' : The Lucene Query Syntax is another query language powered by an open-source search engine library used as a backend for search engines, including Elasticsearch. It is more powerful than KQL but is harder to learn for beginners.
Note: There is another query language abbreviated as KQL, the Kusto Query Language, for use in Microsoft. This is not the same as the Kibana Query Language. So keep this in mind in case you are searching online.
The choice of which syntax to use ultimately depends on the situation and the type of data to search for. This is why, in this room, we’ll be switching from one to the other, which will be communicated throughout.
Special Characters
Before we introduce the queries, it may be important for you to review the following important rules. Knowing this will save you a lot of time figuring out why your query is not working as you want it to.
- Certain characters are reserved in ELK queries and must be escaped before usage.
- Reserved characters in ELK include
+,-,=,&&,||,&,|and!. For instance, using the+character in a query will result in an error; to escape this character, precede it with a backslash (e.g.\+).
Example:
- Say you’re searching for documents that contain the term “
User+1” in the “username” field. - Simply typing
username:User+1in the query bar will result in an error because the plus symbol is reserved. To escape it, typeusername:User\+1, and the query will return the desired result.
Wildcards
Wildcards are another concept that can be used to filter data in ELK. Wildcards match specific characters within a field value. For example, using the * wildcard will match any number of characters, while using the ? wildcard will match a single character.
Now for a wildcard scenario. Say you’re searching for all documents that contain the word “monitor” in the “product_name” field, but the spelling may vary (e.g. “monitors”, “monitoring”). To capture all variants, you can use the * wildcard - product_name:monit* - and the query will return all documents with the word “monitor” in the field, regardless of its suffix.
Similarly, if you’re searching for all documents where the “name” field starts with “J” and ends with “n”, you can use the ? wildcard - name:J?n - The query will match any document where the field value begins with a “J” and ends with an “n” but will only be three characters long.
Understanding the abovementioned will inform you to continue with the advanced queries in the following tasks. But before that, here are some questions for you as a review:
Question and Answers section:
- How do you escape the text “
password:Me&Try=Hack!” (Not including the double quotes)1
password:Me\&Try\=Hack=!
- Using wildcards, what will your query be if you want to search for all documents that contain the words “
hacking” and “hack” in the “activity” field?1
activity:hack*
Nested Queries
Sometimes, values in a data set are nested like in a JSON format. Nested queries allow us to search within these objects without needing an external JSON parser.
Take a look at the dataset below: 
- In the above dataset, the “
comments” field is an array of objects, where each object has an “author” and a “text"field.
1. Let’s start by just returning all entries with value in the comments.author field. We could use the * wildcard as we’ve learned in the previous task:
1
comments.author:*
This would return all entries from 1 to 5. If we then want to search for comments that only contain “Alice”, then we can use this query:
1
comments.author:"Alice"
1
- This will return records 1, 3, and 5, as these entries have Alice as the author.
2. If we also want to look for comments with the word “attack” in it, that is written by Alice. Then we can combine two queries with the AND operator like so:
1
comments.author:"Alice" AND comments.text:attack
Trying it out in Kibana
You can try the above queries within Kibana. Here are the steps:
3. In the Kibana dashboard, open the side panel on the left and click “Discover”.
4. Look for the index pattern dropdown and select the nested-queries index pattern. This would be the data that contains the example dataset for this task. 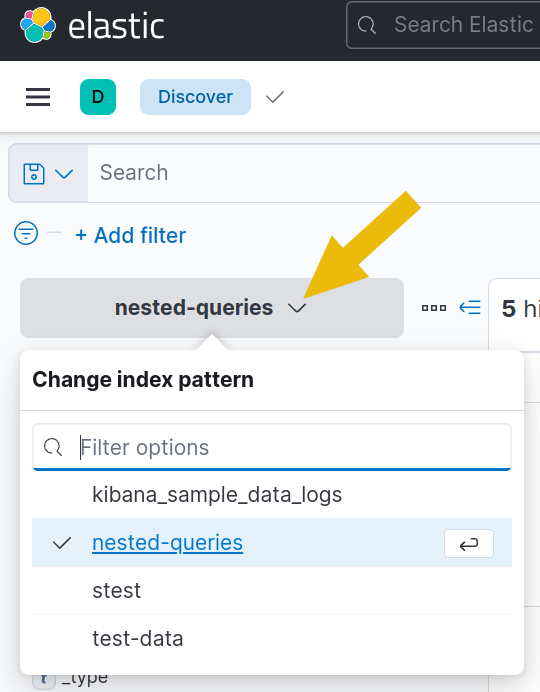
5. Locate the search bar at the top of the page and enter your query here. 
6. Input the queries above to see the results in action. For example, the query comments.author:"Alice" AND comments.text:attack will show the following results: 
1
- You'll notice that "Alice" and "attack" are highlighted in yellow to show you the matched words.
Trying it out with a more extensive data set
You can practice all the queries in this room on a more extensive dataset containing 1000 entries. Use this to practice and answer the questions at the end of every task.
6. Switch to the incidents index dataset and then change the date from Jan 1, 2022, to “Now”. To do so, click the “Show dates” button at the right of the search bar. 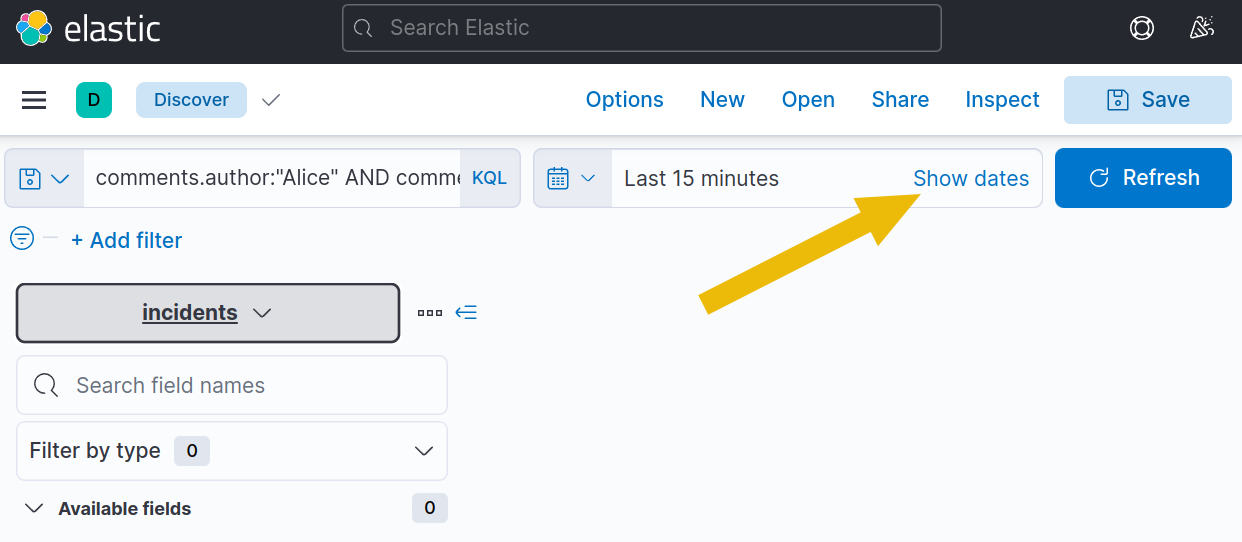
7. Click on “15 minutes ago” to change the starting date. 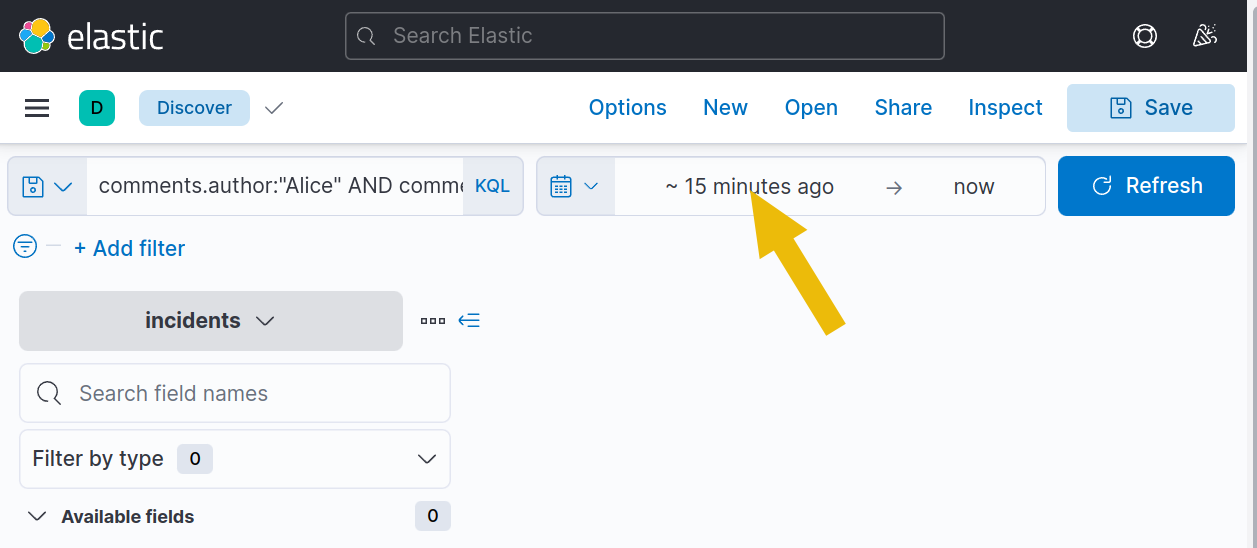
8. And then, set it to Jan 1, 2022, by clicking on the “Absolute” tab, picking the date “Jan 1, 2022 @ 00:00:00.000”, and clicking “Update”. 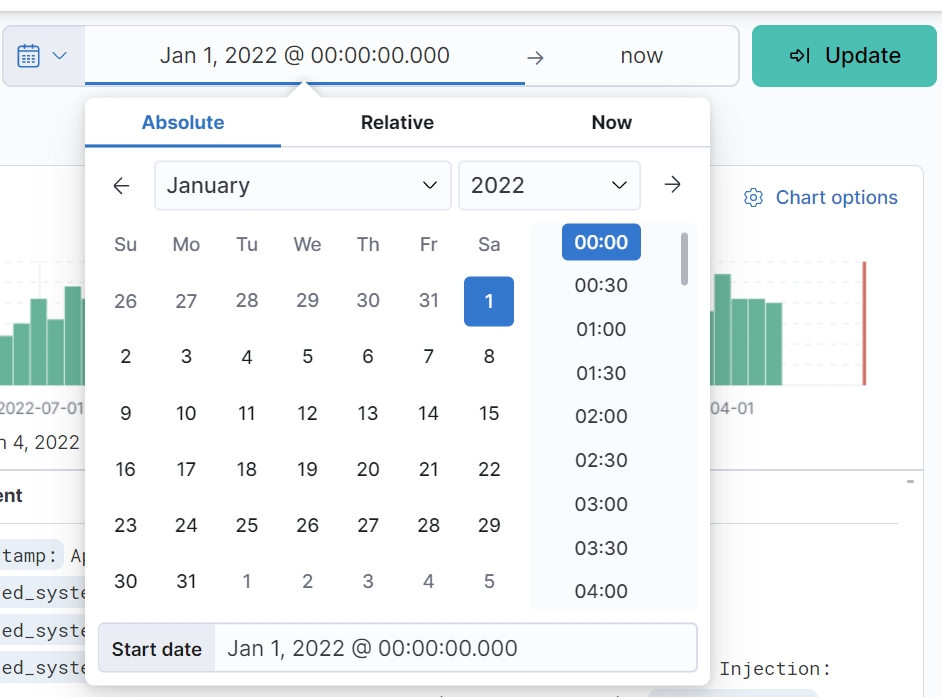
9. You can now search all the data from Jan 1, 2022 up to Now, containing all 1000 entries. 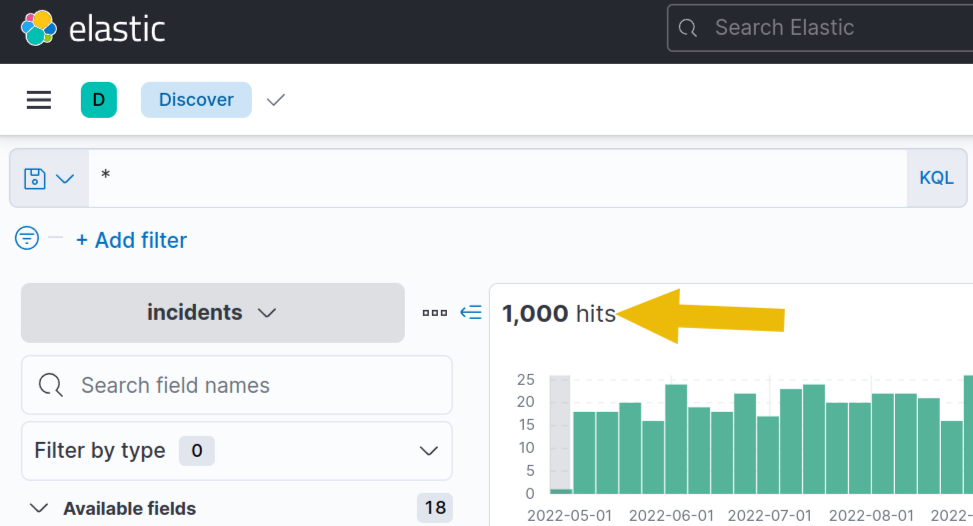
1
- Make sure to replace the search index to "*" to get ALL the events available to us with the given timeline
Question and Answers section:
- Task 3 - Q1 - How many incidents exist where the affected file is “
marketing_strategy_2023_07_23.pptx”?![]()
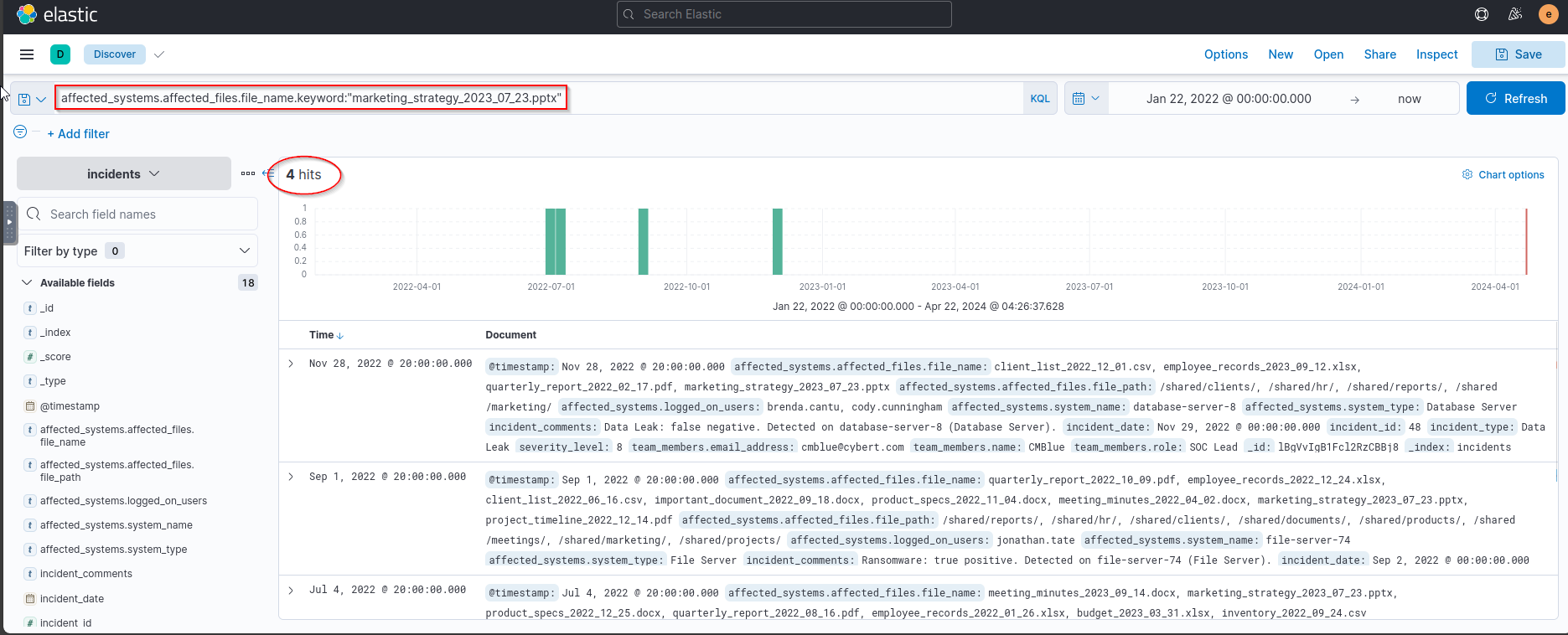
More info about the incident: 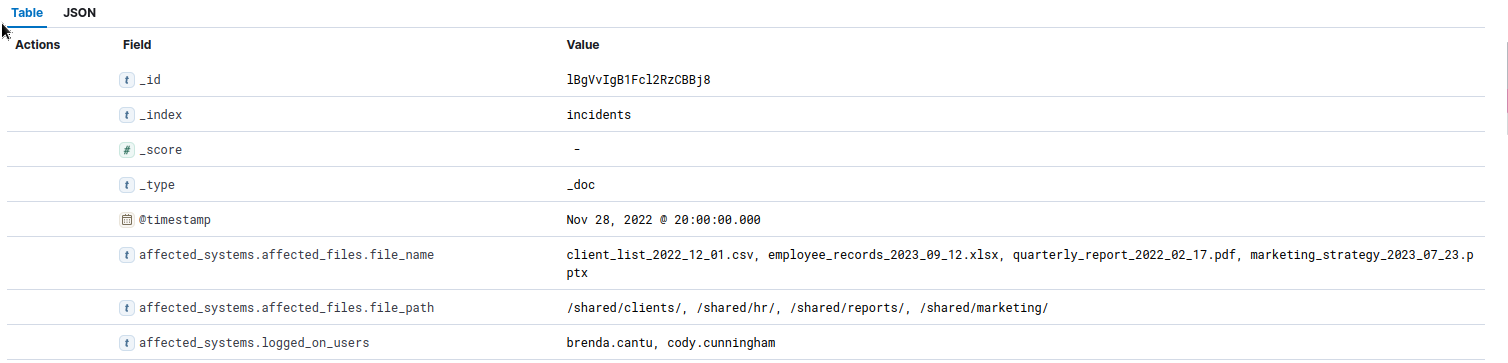
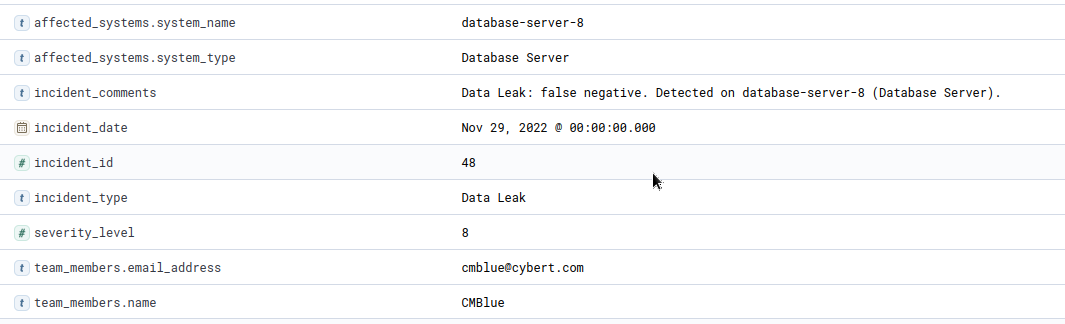
1
- The problem seems to be data exfiltration!
Answer:
1
4
- How many incidents exist where the affected files in
file serversare titled “marketing_strategy”?![]()
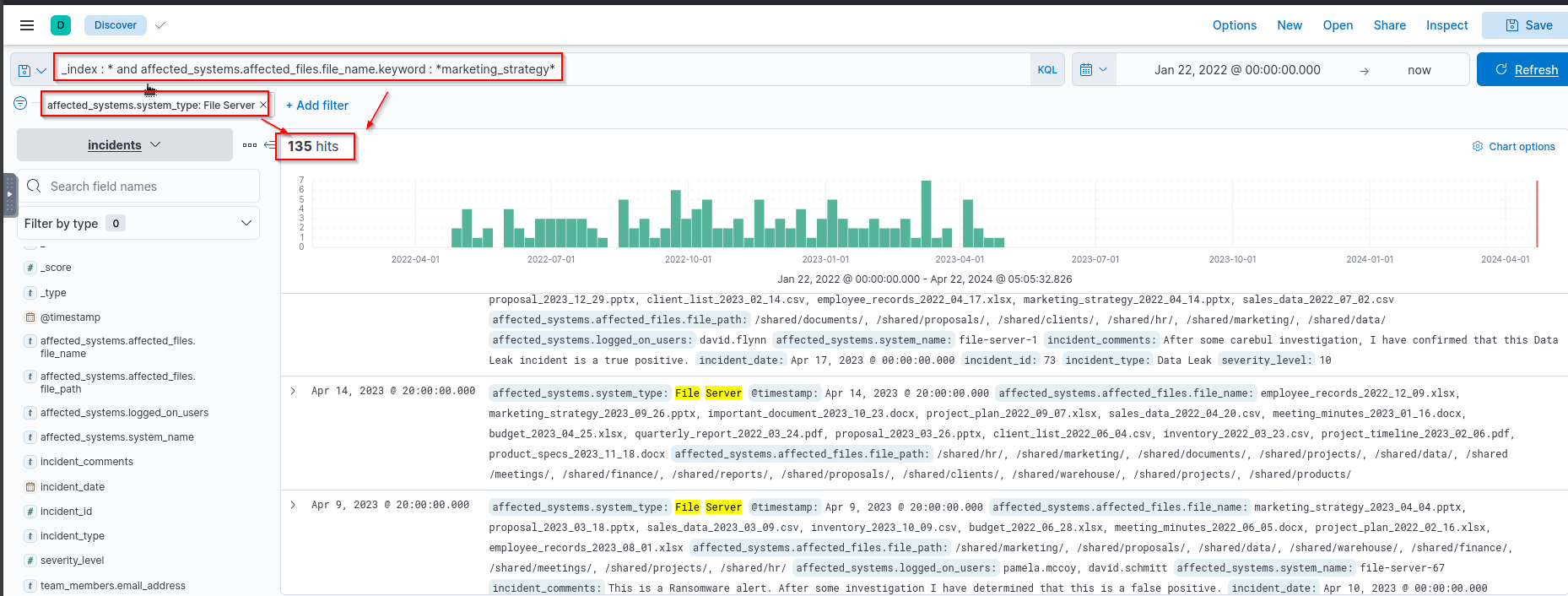
-> There are THREE filters in place:
1
2
3
1. The index
2. The filename with the substring "marketing_strategy"
3. The Server type which is "File Server"
Answer:
1
135
- There is a
true positivealert on awebserverwhere theadminand its users were logged on. What is the name of the webserver?
Query:
1
index = * and affected_systems.logged_on_users.keyword: admin and incident_comments: "*true positive*" and affected_systems.system_name.keyword : *web*
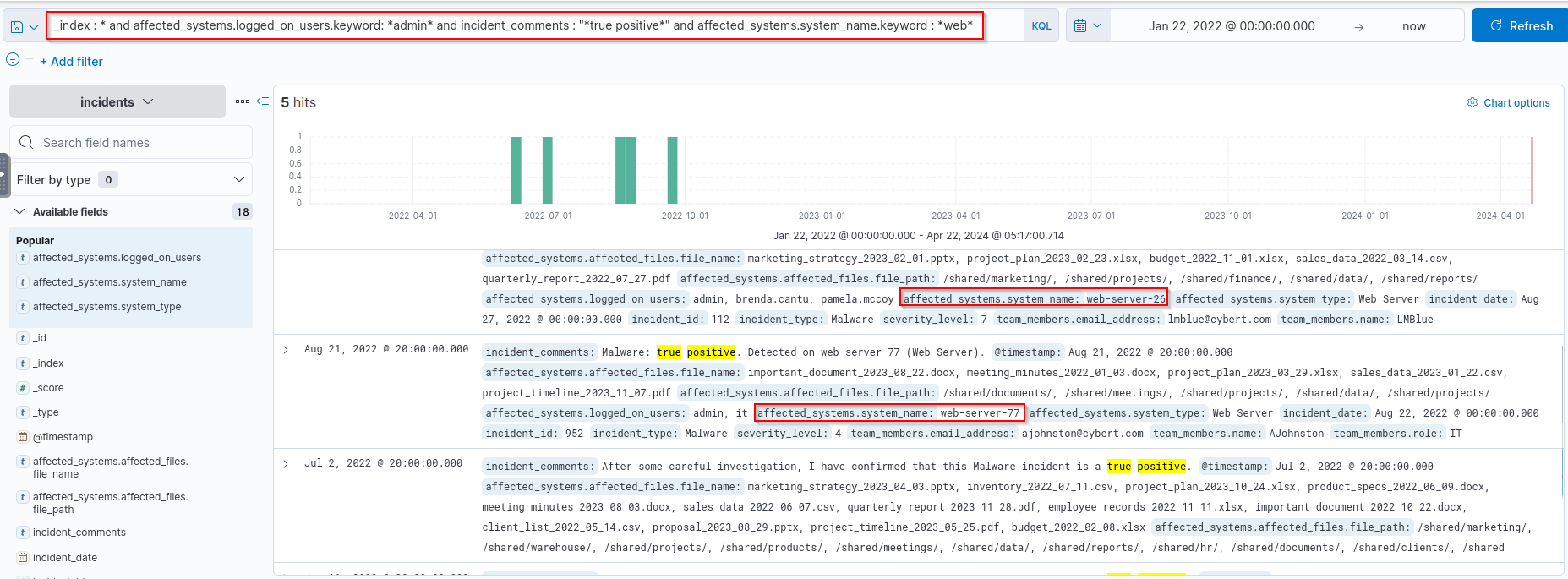
1
2
3
- Not sure which of these two webservers is the answer
- Why is web-server-26 NOT the answer?
- Because the members mentioned in this entry are normal users. What we want are IT users logged on the same time as 'admin'.
Answer:
1
web-server-77
Ranges
Range queries allow us to search for documents with field values within a specified range.
Consider the following example dataset: 
1. To search for all documents where the “response_time_seconds” field is greater than or equal to 100, then the query for you to use is:
1
response_time_seconds >= 100
2. Here’s one for less than 300:
1
response_time_seconds < 300
3. And, of course, these can be combined with an AND operator:
1
response_time_seconds >= 100 AND response_time_seconds < 300
1
- The query will return the documents with alert_id 1, 2, and 5.
4. Ranges are beneficial for dates, which you’ll get to try in Kibana in a later section. There are different ways to search by ranges, and one way is by specifying the date by following specific formats.
1
@timestamp<"yyyy-MM-ddTHH:mm:ssZ"
5. The time is optional, so you can also do the following:
1
@timestamp>yyyy-MM-dd
Trying it out in Kibana
Like in the previous task, you can try the above queries by changing the index, this time to ranges.
Use the query response_time_seconds >= 100 AND response_time_seconds < 300 and you should see the following results:
Output: 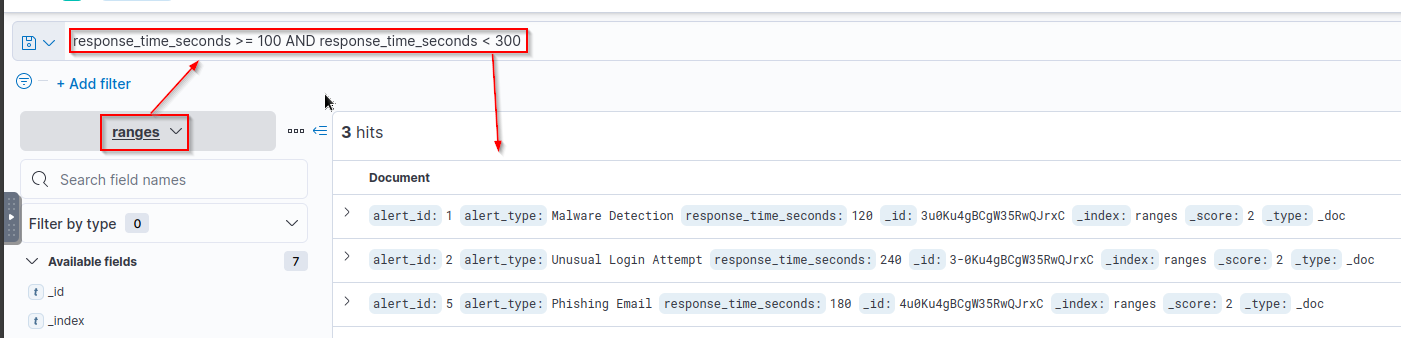
Trying it out with a more extensive data set
Now that you’ve seen how it works, let’s switch back to the incidents dataset and use the lessons you’ve learned in this task to answer the questions below:
- How many “
Data Leak” incidents have a severity level of 9 and up? Query:1
severity_level >= 9 AND incident_comments : *leak*
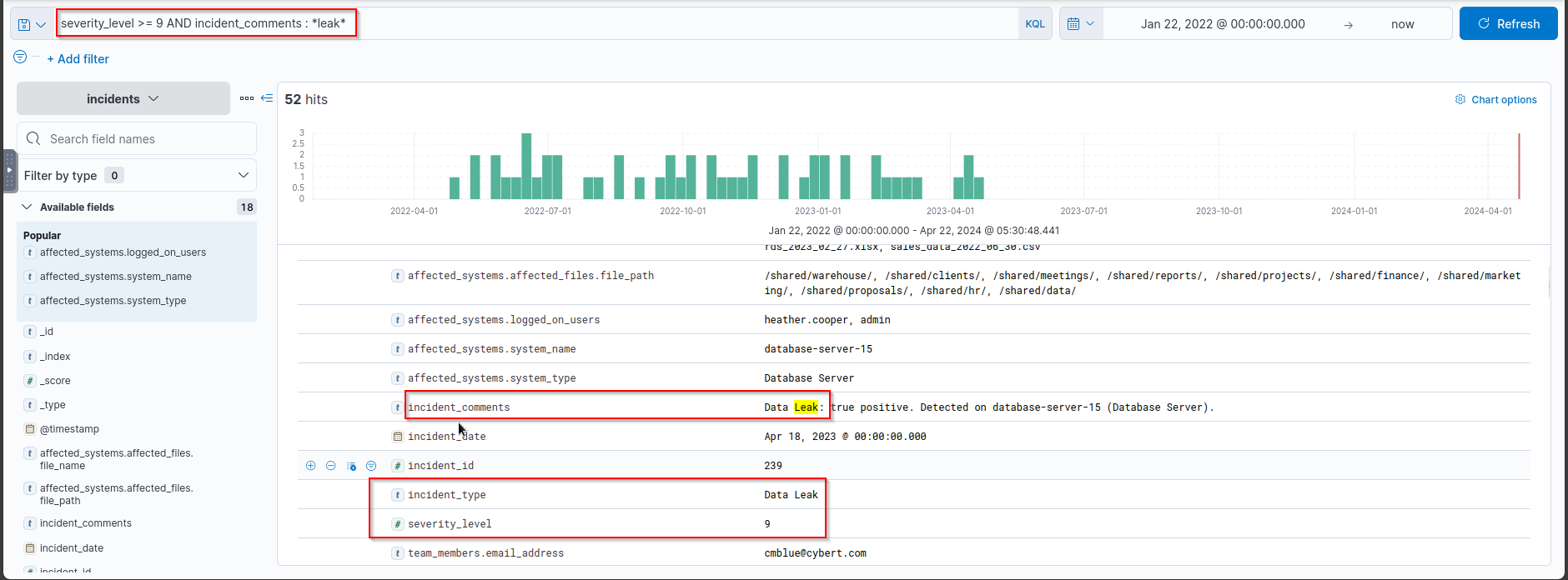
Answer:
1
52
- How many incidents before
December 1st, 2022hasAJohnstoninvestigated where the affected system is either anEmailorWeb server?![]()
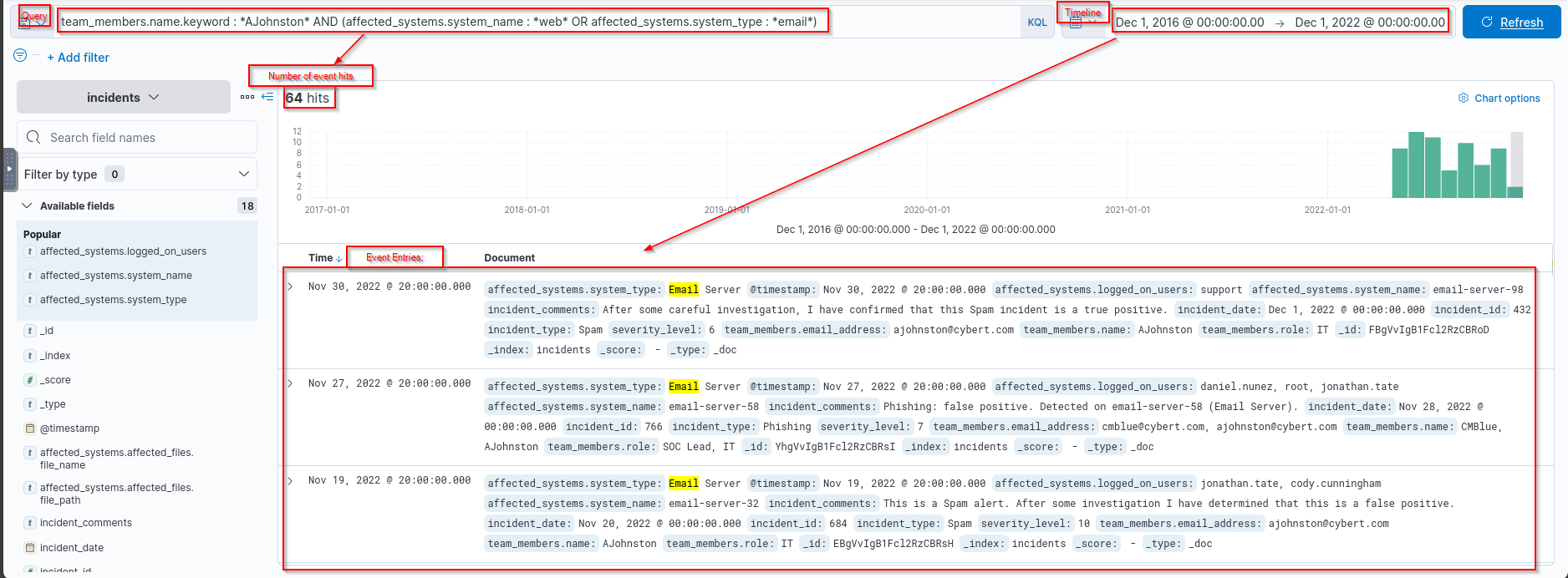
Answer:
1
51
- From the
incident IDs 1 to 500, what is theemail addressof theSOC Analystthat left a comment on an incident that thedata leakonfile-server-65is afalse positive? Query:1
(incident_id >= 1 AND incident_id <= 500) AND incident_comments : *leak* AND affected_systems.system_name : "file-server-65" and incident_comments : "*false positive*"
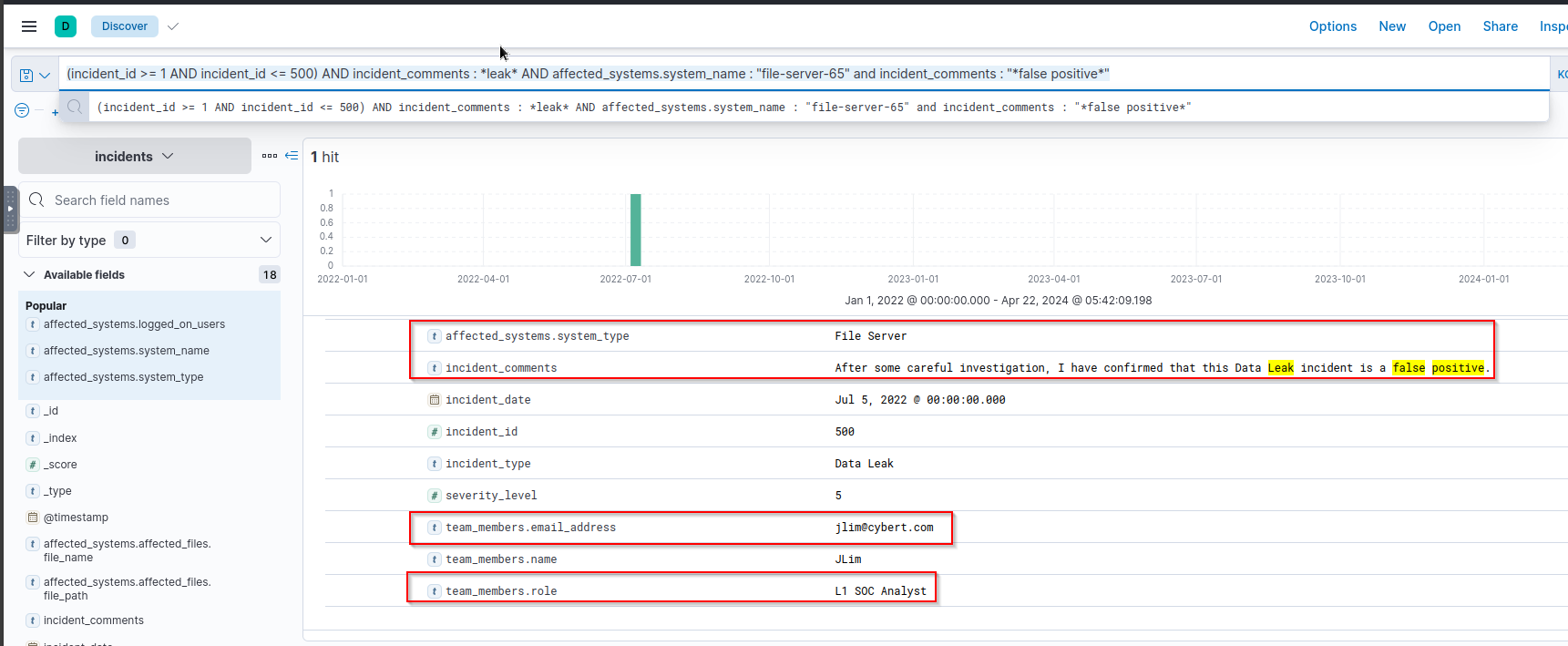
Answer:
1
jlim@cybert.com
Fuzzy Searches
Fuzzy searching is beneficial when searching for documents with
inconsistenciesortyposin the data.It accounts for these variations and retrieves relevant documents by allowing a specified number of character differences (known as the fuzziness value) between the search term and the actual field value.
0. For example, if you want to search for “server”, you can use a fuzzy search to return documents containing “serber”, “server01”, and “server001”. See below: 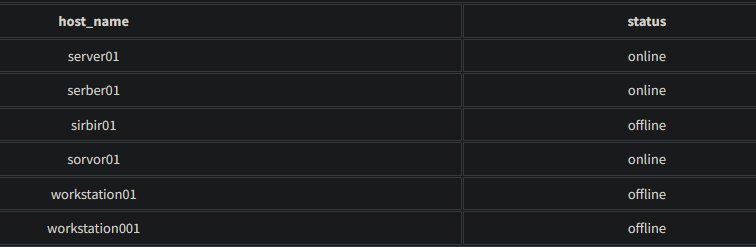
1. To search for all documents where the “host_name” field is similar, but not necessarily identical to “serber”, you can use the following query:
1
host_name:server01~1
As you can see, the “~” character indicates that we are doing a fuzzy search. The format of the query is as follows:
1
field_name:search_term~fuzziness_value
Using the query above will return the following documents:
1
2
3
4
5
6
7
8
{
"host_name": "server01",
"status": "online"
},
{
"host_name": "serber01",
"status": "online"
}
2. The fuzziness value lets us control how many characters differ from the search term. A fuzziness of 1 returns the documents above. A fuzziness of 2 returns only the following:
1
host_name:server01~2
1
{ "host_name": "server01", "status": "online" }, { "host_name": "serber01", "status": "online" }, { "host_name": "sorvor01", "status": "online" },
One important thing to note, however, is that fuzzy searching does NOT work on nested data and only matches on one-word strings. Despite the limitations, it is still useful, especially for finding typos.
Trying it out in Kibana
3. Return to Kibana and change the index to fuzzy-searches. This time, however, we will be switching our syntax system to use Lucene instead of KQL, as boosting only works in Lucene.
To do this, click on the “KQL” button to the right of the search bar, and then on the pop-up window, set the “Kibana Query Language” option from “On” to “Off”. This means that all queries going forward will now use “Lucene”. 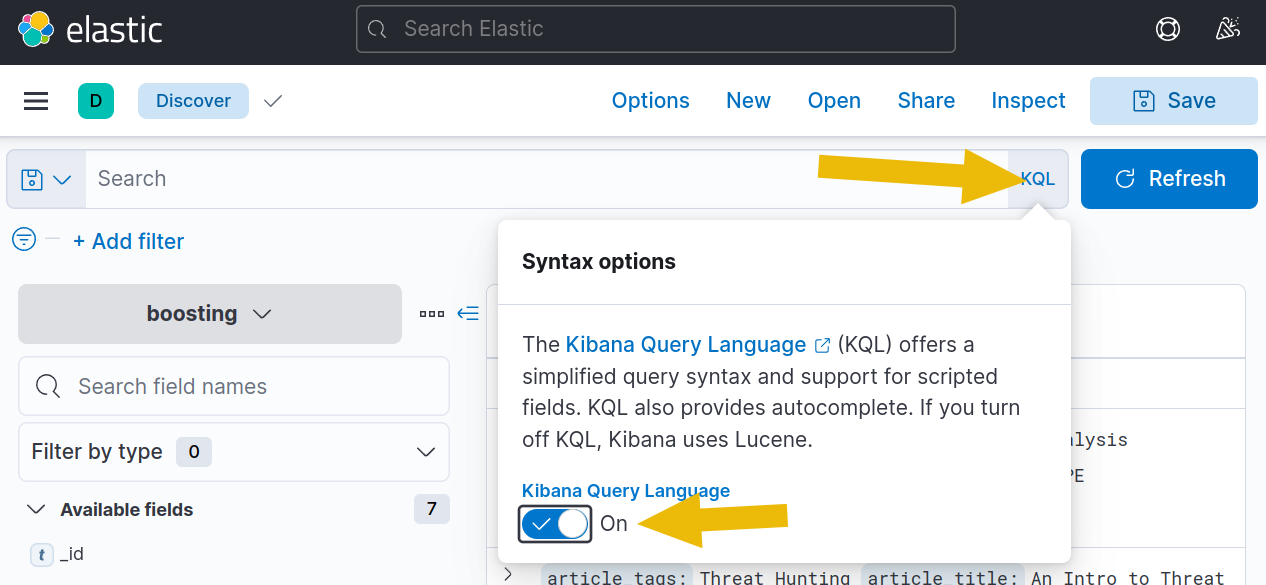
4. With this correctly set up, use host_name:server01~1 as a query, and then you should get the following results: 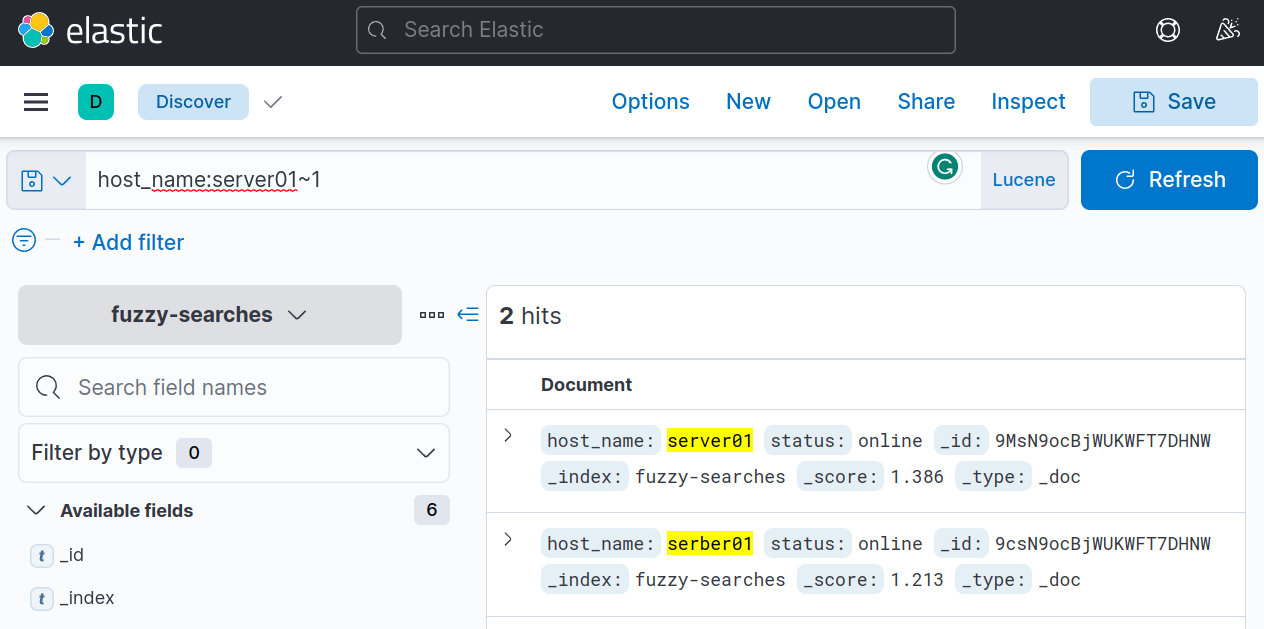
5. Fuzzy searching also works even if the number of characters of the word is not the same. For example, a search query of host_name:workstation01~1 would result in the following: 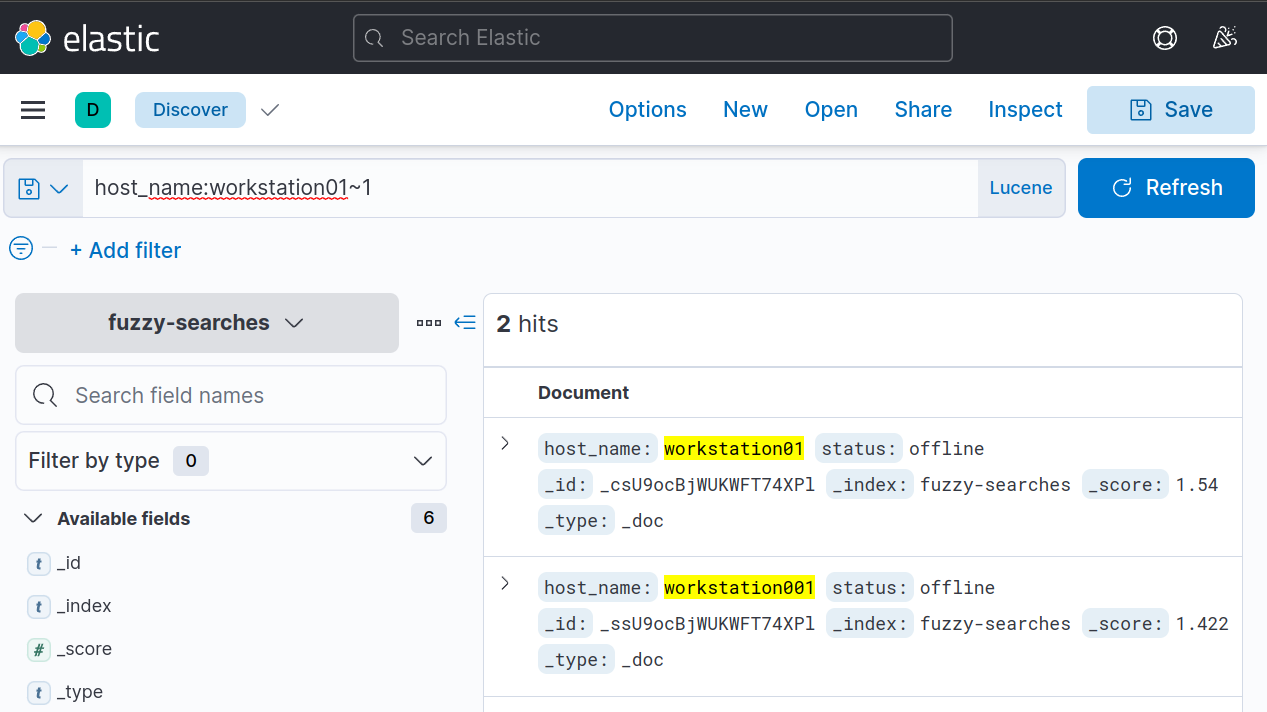
Trying it out with a more extensive data set
Let’s experiment some more by switching to the incidents index dataset and by answering the questions below:
Note: For this task, make sure that you are using Lucene query syntax.
- Including the misspellings, how many incidents has
JLimhandled where he misspelt the word “true”? Query:1
team_members.name : JLim AND incident_comments : true~2
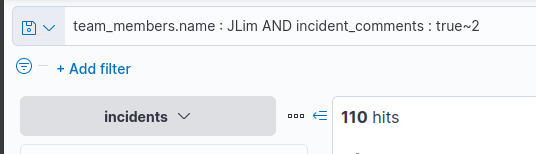
Answer:
1
110
- How many incidents has
JLimhandled where he misspelt the word “negative”?![]()
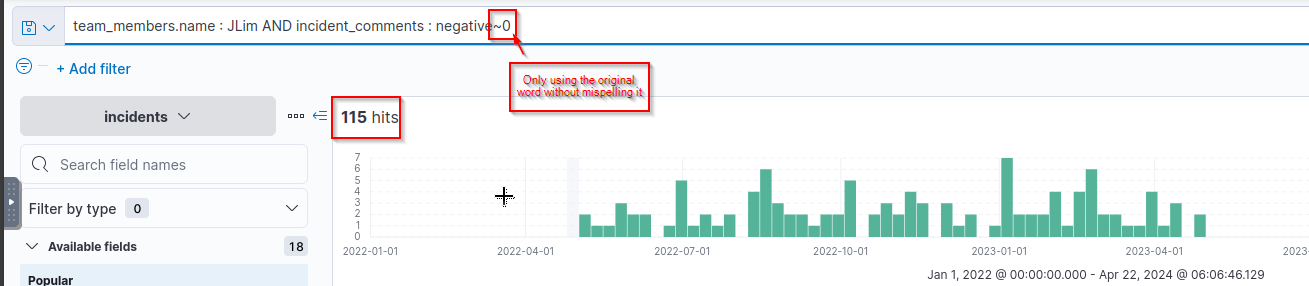
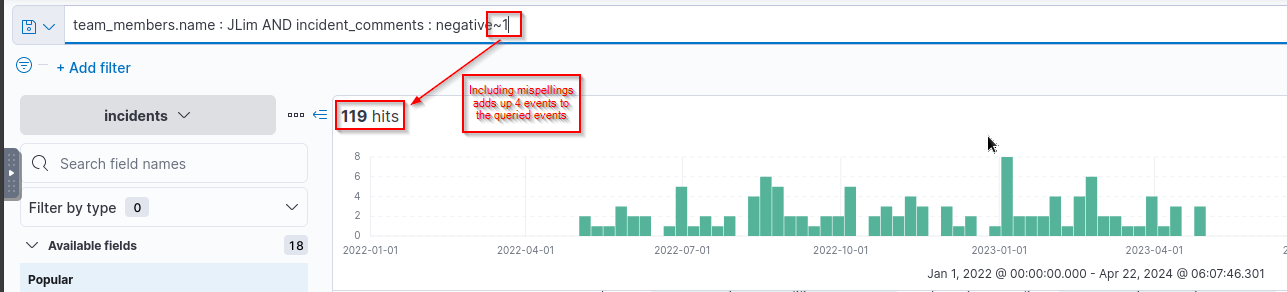
Answer:
1
4
Proximity Searches
- Proximity searches allow you to search for documents where the field values contain two or more terms within a specified distance.
0. In KQL, you can use the match_phrase query with the slop parameter to perform a proximity search. The slop parameter sets the maximum distance that the terms can be from each other.
Example:
1
-> A slop value of 2 means that the words can be up to 2 positions away.
The format when doing a proximity search is like so:
1
field_name:"<search term>"~<slop_value>
1. As you can see, the “~” character is used, followed by a slop_value.
Note that “~” is used for both proximity searches and fuzzy searching; the difference is that in proximity searches, the slop value is applied to a phrase enclosed in quotation marks (").
Let's continue. Consider the following example dataset: 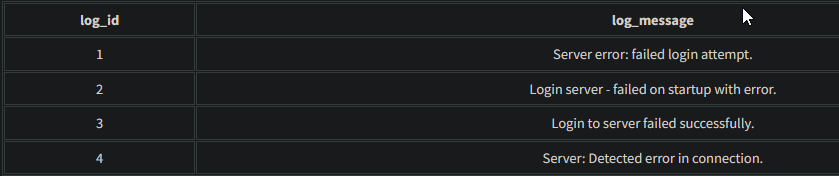
2. To search for all documents where the terms “server” and “error” appear within a distance of 1 word or less from each other in the “log_message” field, you can use the following query:
1
log_message:"server error"~1
This query will return the following documents:
1
{ "log_id": 1, "log_message": "Server error: failed login attempt." }, { "log_id": 4, "log_message": "Server: Detected error in connection." }
1
2
- On the second choice, there's one word in between the words "Server" and "error" which is "Detected".
- I guess the ":" and spaces are taken into account as well?
3. You can see in the results above that “server” and “error” have one word or less in between them.
If we change our query to:
1
log_message:"failed login"~0
Then we’ll end up with just:
1
2
3
4
{
"log_id": 1,
"log_message": "Server error: failed login attempt."
}
Trying it out in Kibana
4. We’re still going to be using Lucene for this task. Change the index pattern to proximity-searches and use the following query:
1
log_message:"server error"~4 // note that this is used for the distance of FIVE words
This should give us the results below. Notice, in the 3rd result, there are four words between “server” and “error”. 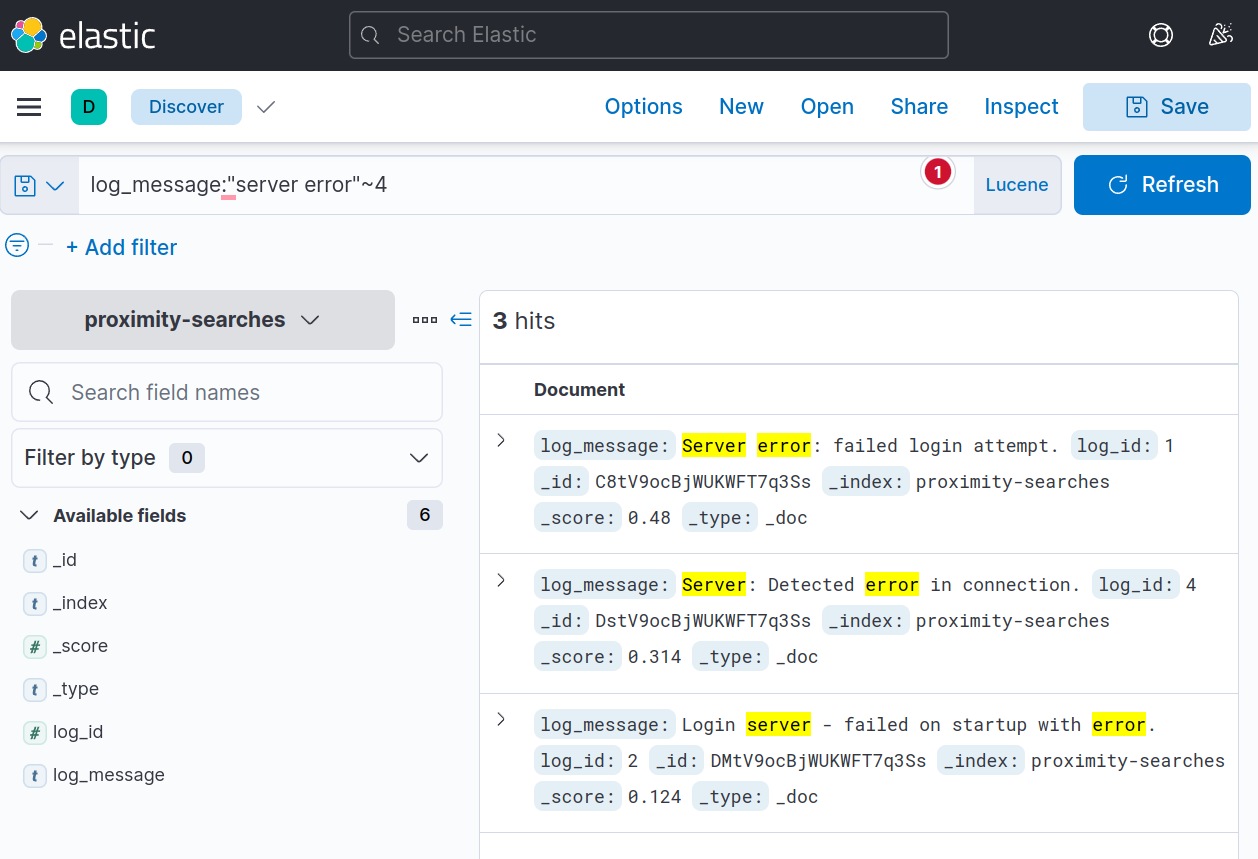
1
- Note that on the last one, it has to take into account the character "-" and possibly treated it as a word? Not sure
5. You can also use operators such as AND and OR in more complex queries for multiple proximity searches. For example, if you want to search for documents containing either “failed login” or “server error” within a distance of 2 words, you could use the following query:
1
log_message:"server error"~1 OR "login server"~1
Which will return the following documents: 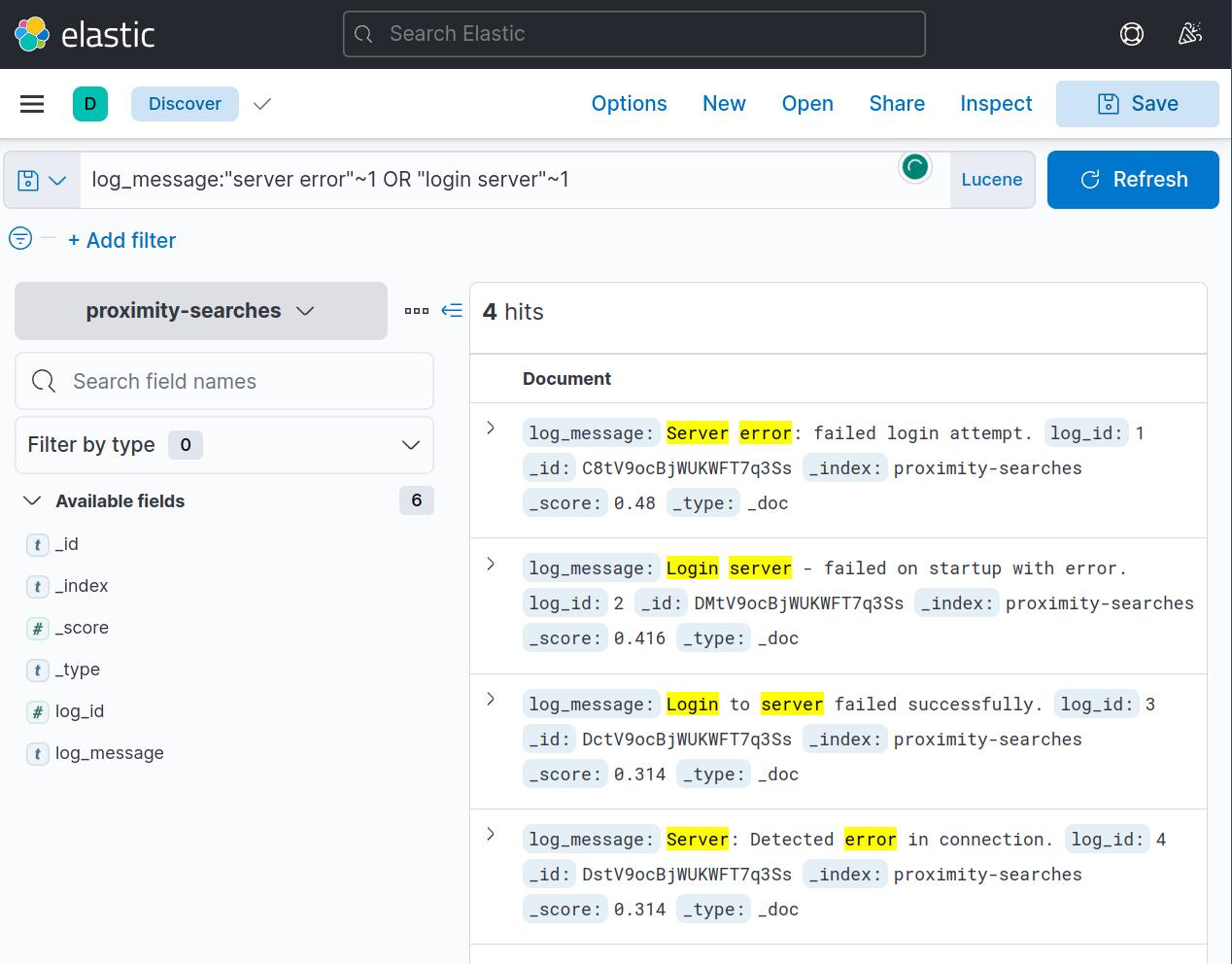
Trying it out with a more extensive data set
Now for an even more significant challenge, switch to the incidents index dataset and answer the questions below:
Note: For this task, make sure that you are using Lucene query syntax.
- How many incidents are there when you want to look for the words “
data leak” and “true negative” in the comments that areat least 3 words in betweenthem?
Possible Query:
1
incident_comments:"data leak"~3 AND "true negative"~3
1
- This is INCORRECT because it groups up the two words "data leak" and "true negative" and measure up the slop value on each other.
Another Query:
1
incident_comments:"data leak true negative"~3
1
- With this one, EACH WORD is measured up on one another based on the slop value to the distance of each words against one another.
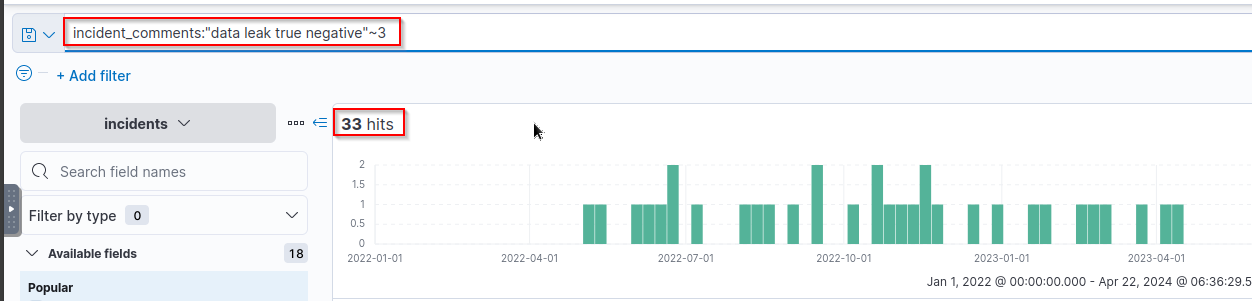
Answer:
1
33
- How many incidents has
AJohnstoninvestigated that have the words “detected” and “negative” in the comments that aretwo words apart? Possible Query:1
team_members.name : AJohnston AND (incident_comments : "detected negative"~2)
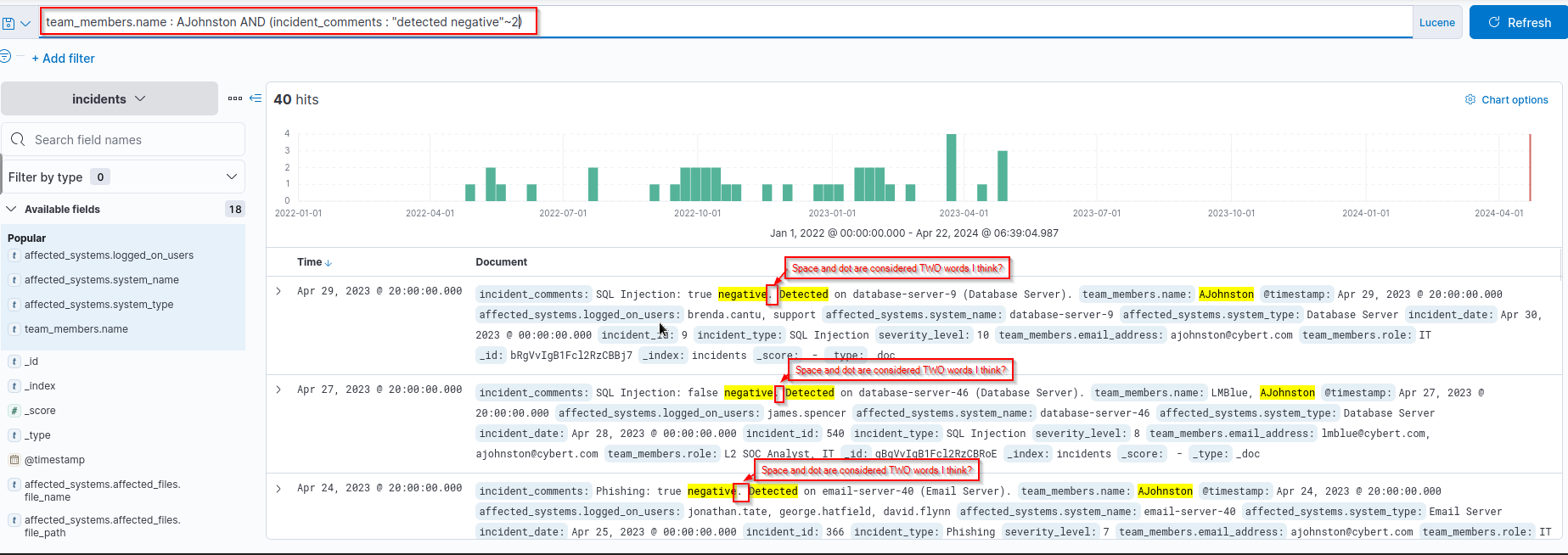
Answer:
1
40
Regular Expressions
Regular expressions (or regex, regexp) allow you to use a pattern to match field values. You’ll encounter this powerful concept frequently when working with data. We can use regexp in Kibana to search for complex patterns that cannot easily be found using simple query strings or wildcards.
Before you continue, I encourage you to check out the Regexp room. That room will cover the basics of regular expressions and give you most of what you need to grasp better what is covered in this task.
Trying it out in Kibana
0. You’ll notice that we’re heading straight to Kibana this time. This is because regular expressions can get confusing if you don’t know what you are doing. Thankfully, Kibana highlights matches in the documents we’ll use to verify our expressions.
Like before, please change the index pattern to:
1
regular-expressions
Consider the following dataset: 
1. To use regex in a query, you must wrap your regular expression in forward slashes (/). Let’s start with a relatively simple example and use “.*” to match all characters of any length.
1
Event_Type:/.*/
This will return all the entries, as shown below: 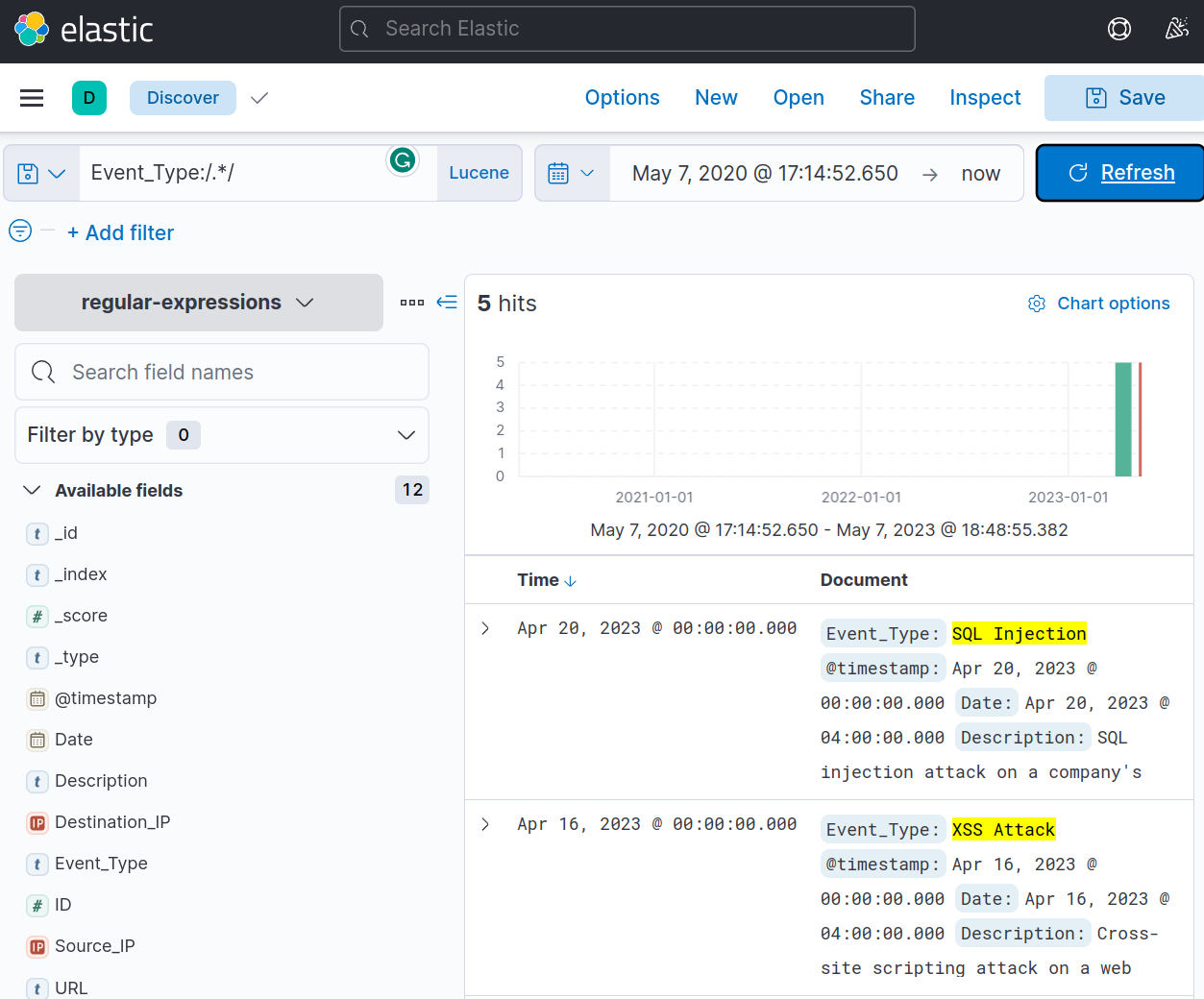
1
- Notice that all entries of "`Event_Type`" that matched are highlighted in Yellow.
1. If we want only to return entries that start with the letters “S” or “M”, then we could use the following:
1
Event_Type:/(S|M).*/
This will return only the entries that start with S and M, as shown below: 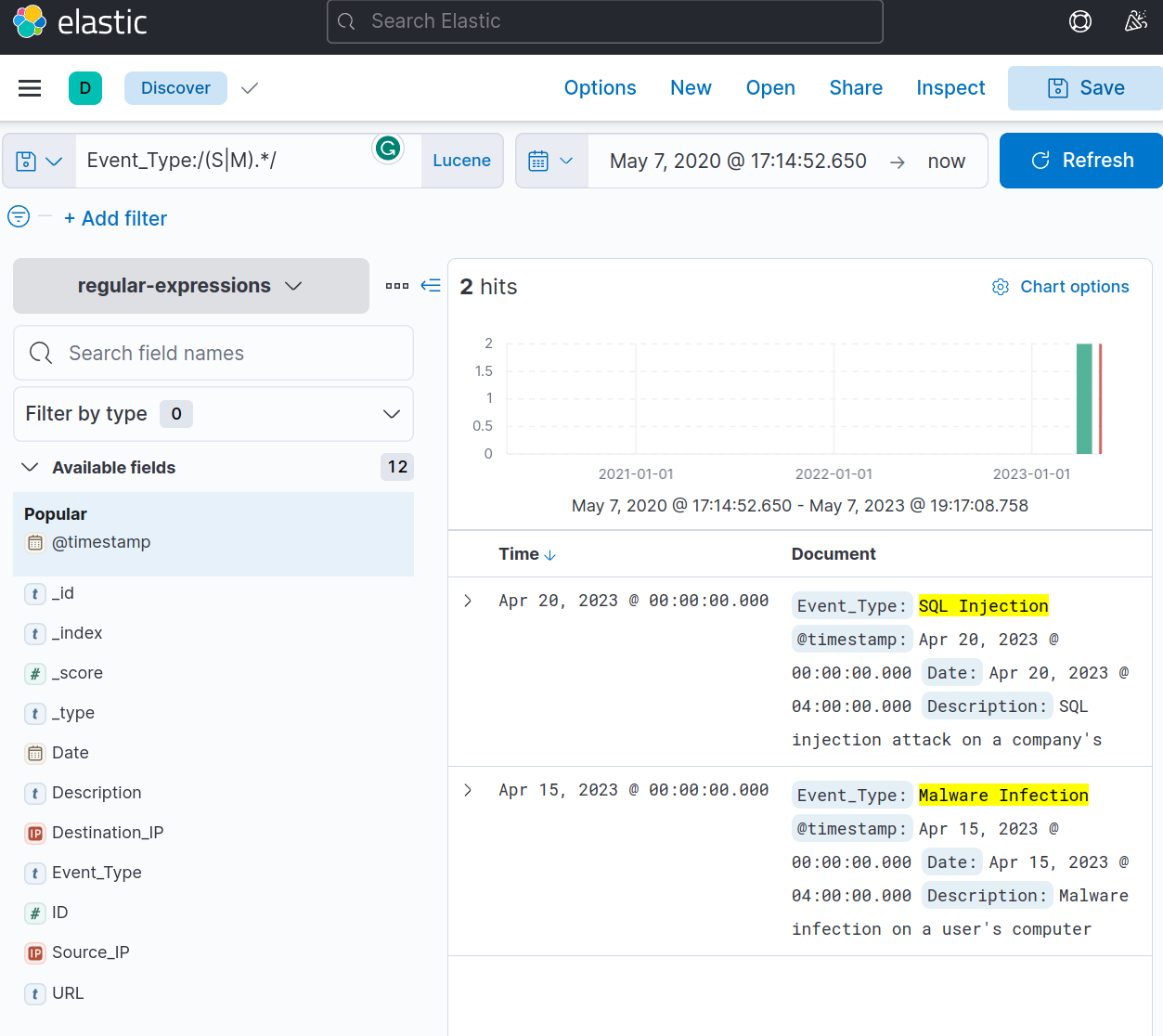
1
- One important thing to note about Kibana's regex engine is that its behaviour changes depending on the data type.
2. So far, we’ve used regex on the “Event_Type” field. And the data type for this field is set internally to “keyword”. Regular expressions behave as you’d expect when searching for data with this type.
The behaviour changes if the data type is set to “text”. For example, the field “Description” has “text” as its data type.
Try the following query:
1
Description:/.*/
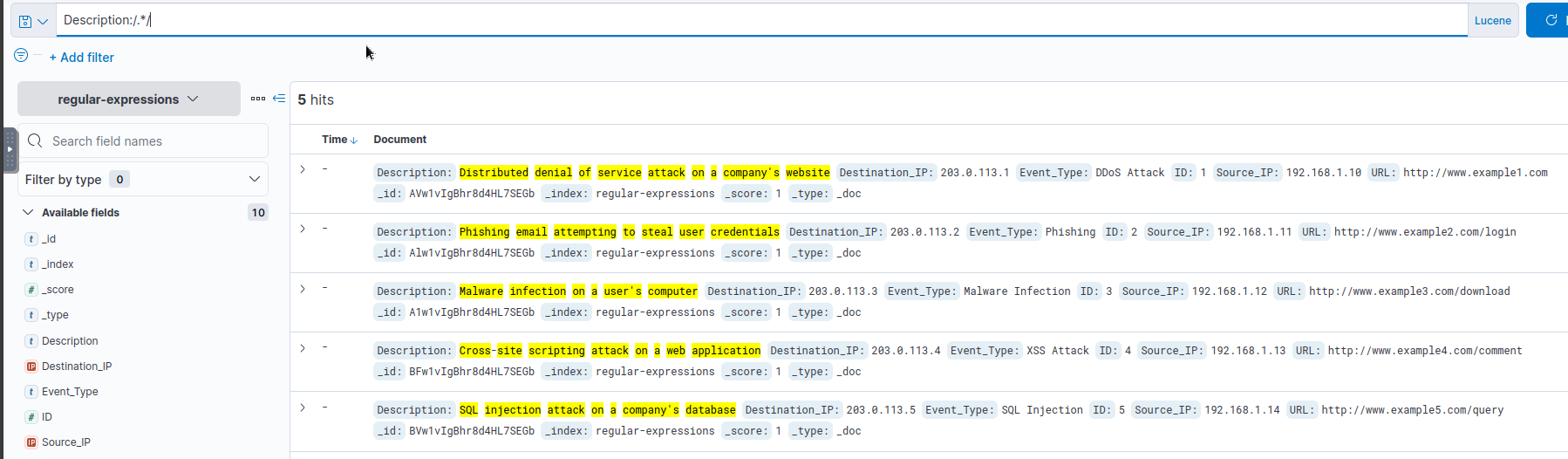
1
- So far, so good. All the entries are returned because we match all characters of any length.
3. Now this is where things change. Try the following query and check the results:
1
Description:/(s|m).*/
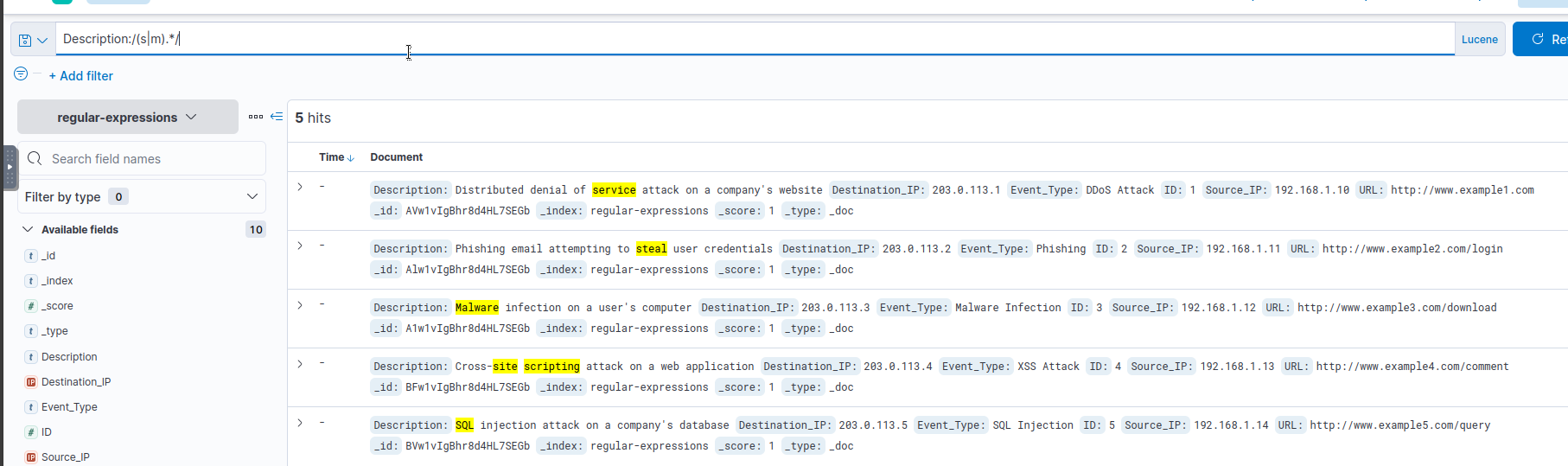
1
2
3
- Notice that instead of the whole description being highlighted in yellow, only single words starting with the letters "s" or "m" are highlighted.
- This is because when a text field is analyzed, the string is "tokenized", and the regular expression is matched against each word.
- This is why the words "SQL", "steal", "service", and even "site" from "Cross-site scripting" is highlighted.
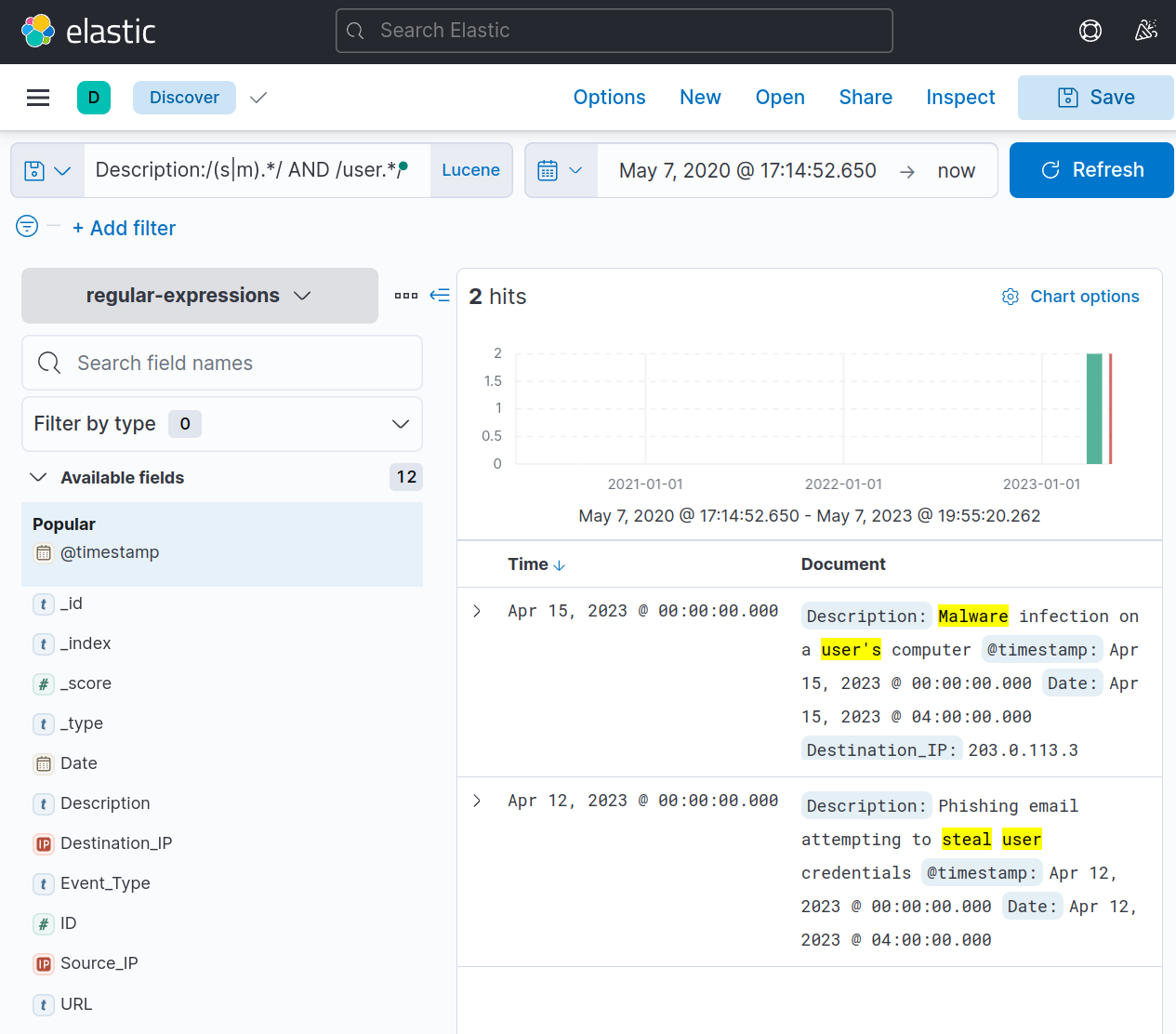
4. This approach allows for flexibility which can be further utilized by combining it with more expressions, as shown below:
1
Description:/(s|m).*/ AND /user.*/
Question and Answers section:
Trying it out with a more extensive data set
Almost there! Switch to the incidents index dataset and answer the questions below:
Note: For this task, make sure that you are using Lucene query syntax.
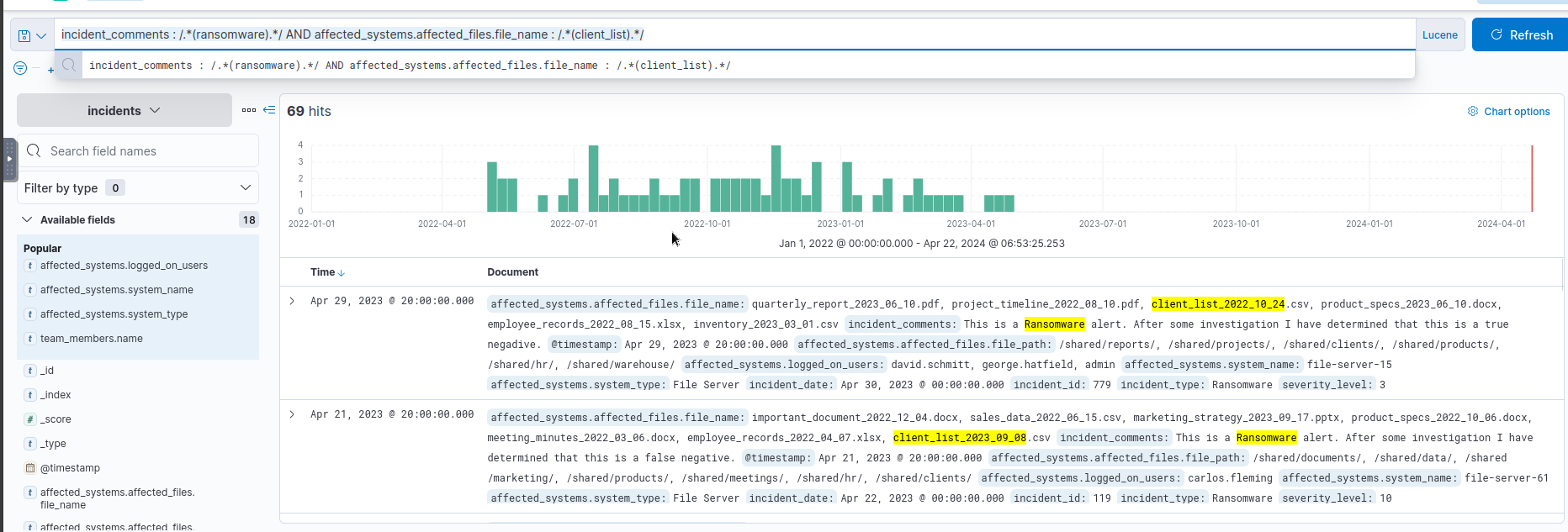
- How many incidents are there where a “
client_list” file was affected byransomware?
Query used:
1
incident_comments : /.*(ransomware).*/ AND affected_systems.affected_files.file_name : /.*(client_list).*/
- What is the
nameof theaffected systemat theearliest incident datethatEVenisinvestigated with afilenamecontaining the word “project”? Query:1
team_members.name : Evenis AND affected_systems.affected_files.file_name: /.*(project).*/
![]()
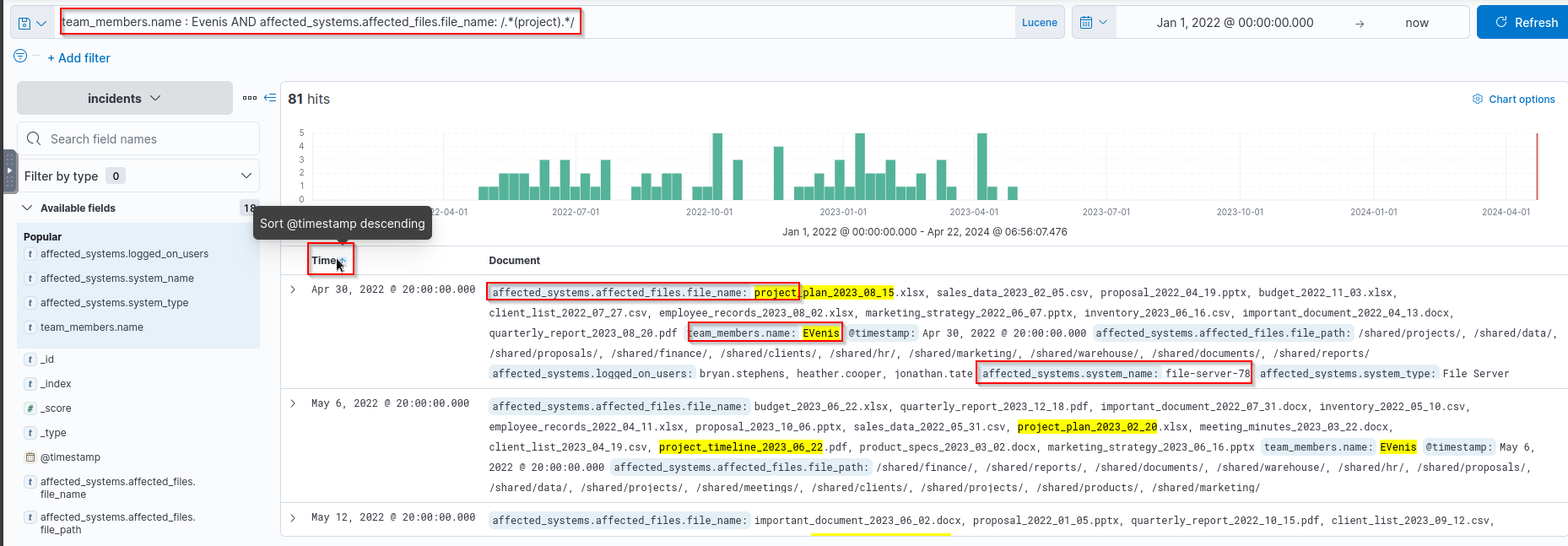
Answer:
1
file-server-78
Conclusion
Throughout this room, we have explored various advanced querying techniques in Kibana, which are instrumental in helping analysts effectively filter, manipulate, and extract valuable insights from large datasets in the cyber security domain. These techniques empower analysts to go beyond basic queries and delve deeper into the data, uncovering hidden patterns and correlations that can inform decision-making and enhance problem-solving capabilities.